Project Overview
VeriReason introduces a novel approach utilizing reinforcement learning with testbench feedback to enhance the performance of pre-trained models for Verilog RTL code generation. Our method combines supervised fine-tuning with Guided Reward Proximal Optimization (GRPO) reinforcement learning, establishing a new state-of-the-art for automated RTL synthesis.
Framework Architecture
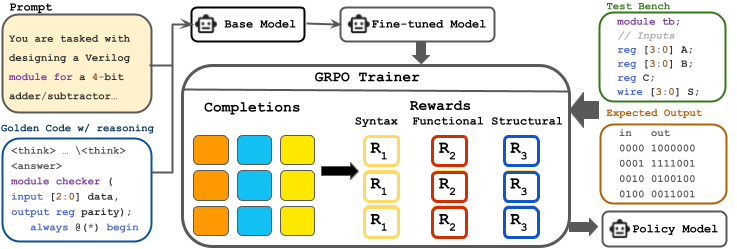
The framework combines supervised fine-tuning with GRPO reinforcement learning, leveraging testbench feedback for comprehensive Verilog code generation optimization.
Step 1: Data Preparation & Reasoning Augmentation
We start with the RTLCoder dataset and apply comprehensive filtering and augmentation:
- Syntax validation to ensure code correctness
- GPT-4 validation for prompt-code alignment
- Reasoning step generation with <think> blocks
- Comprehensive testbench generation (100+ test cases)
- Difficulty-based stratification (easy/hard splits)
Step 2: Supervised Fine-Tuning (SFT)
Fine-tune base models on curated reasoning-enhanced dataset:
# SFT Training Command
llamafactory-cli train qwen2.5_7b.yaml
# Custom Script Alternative
chmod +x run_rtl_training.sh
./run_rtl_training.sh
This stage establishes foundational Verilog understanding with explicit reasoning capabilities.
Step 3: GRPO Reinforcement Learning
Optimize policy using Group Relative Policy Optimization with multi-faceted rewards:
- Multi-faceted reward system: Combines syntax, functional, and structural correctness
- Testbench-driven feedback: Real-time verification using comprehensive test suites
- Group-based optimization: Compares multiple candidate solutions for better learning
- Policy gradient methods: Iterative improvement through reinforcement signals
The GRPO framework enables the model to learn from both positive and negative examples, developing self-checking capabilities and improving first-attempt functional correctness by up to 2.8× compared to baseline methods.
Step 4: Comprehensive Evaluation
Validate performance on industry-standard benchmarks:
- VerilogEval-Machine: 143 algorithmically generated specifications
- VerilogEval-Human: 156 human-written specifications
- Metrics: pass@1, pass@5 functional correctness
- Comparison: Against GPT-4 Turbo, commercial systems
Interactive Examples
4-Bit Adder with Carry Implementation
Explore how VeriReason approaches complex Verilog design tasks with explicit reasoning and structured implementation.
Technical Methodology
Reward Model Design
ASTscore(o) = ∑c∈C wc·(0.6·simc + 0.5·covc - 0.3·redc)
GRPO Optimization
Data Filtration Strategy
Adaptive two-stage filtering optimizes training effectiveness:
Difficulty score: δ(s) = 1 - (μr(s) - αmin)/(αmax - αmin)
This yields 1149 hard samples and 743 easy samples for targeted training.
Available Models
VeriReason-Qwen2.5-1.5B
Efficient 1.5B parameter model optimized for resource-constrained environments while maintaining strong performance.
VeriReason-Qwen2.5-3B
Flagship 3B parameter model combining SFT with GRPO reinforcement learning for state-of-the-art RTL generation.
VeriReason-Qwen2.5-7B-SFT
7B parameter model with supervised fine-tuning for enhanced reasoning capabilities in Verilog generation.
VeriReason-Llama-7B-GRPO
7B parameter Llama-based model with GRPO training demonstrating architecture generalizability.
Training Datasets
RTL-Coder Small
Filtered baseline dataset without reasoning components, ideal for initial training and comparison studies.
RTL-Coder 7B Reasoning TB Simple
Simplified reasoning dataset with testbench feedback for enhanced model training and validation.
RTL-Coder 7B Reasoning TB
Full reasoning dataset with comprehensive testbench feedback integration and explicit reasoning steps.
RTL-Coder 7B Combined
Comprehensive combined dataset incorporating all reasoning and testbench feedback components for full training.
Training & Usage
Supervised Fine-Tuning (SFT)
Fine-tune base models on curated reasoning-enhanced dataset using two methods:
# Method 1: Using LlamaFactory llamafactory-cli train qwen2.5_7b.yaml # Method 2: Custom training script # Move sft_rtl to src/open_r1/ chmod +x run_rtl_training.sh ./run_rtl_training.sh
GRPO Reinforcement Learning
Optimize policy using Group Relative Policy Optimization with multi-faceted rewards:
# Move necessary files mv verilog_rewards_tb.py verilog_train_tb.py src/open-r1/ # Create recipe directory mkdir verilog_recipe mv verilog_grpo_tb.yaml verilog_recipe/ # Launch GRPO training NCCL_DEBUG=INFO TORCH_DISTRIBUTED_DEBUG=DETAIL \ CUDA_VISIBLE_DEVICES=5,6,7 ACCELERATE_USE_NCCL=1 \ accelerate launch --config_file recipes/accelerate_configs/zero3.yaml \ --num_processes=3 src/open_r1/verilog_train_rtlcoder.py \ --config verilog_recipe/verilog_grpo_tb.yaml --use_vllm=false
System Requirements
Hardware
- CUDA-compatible GPUs
- Multi-GPU recommended
- 16GB+ VRAM per GPU
Software
- PyTorch with CUDA support
- Accelerate library
- NCCL for distributed training
Tools
- Iverilog simulator
- LlamaFactory (optional)
- Open-R1
Citation
BibTeX Entry
@misc{wang2025verireasonreinforcementlearningtestbench,
title={VeriReason: Reinforcement Learning with Testbench Feedback
for Reasoning-Enhanced Verilog Generation},
author={Yiting Wang and Guoheng Sun and Wanghao Ye and Gang Qu and Ang Li},
year={2025},
eprint={2505.11849},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2505.11849},
}